Spark é uma forma de processamento distribuído que opera no ecossistema Big Data. Vamos dar uma explorada nos seus principais componentes, na sua arquitetura e no seu funcionamento.
-
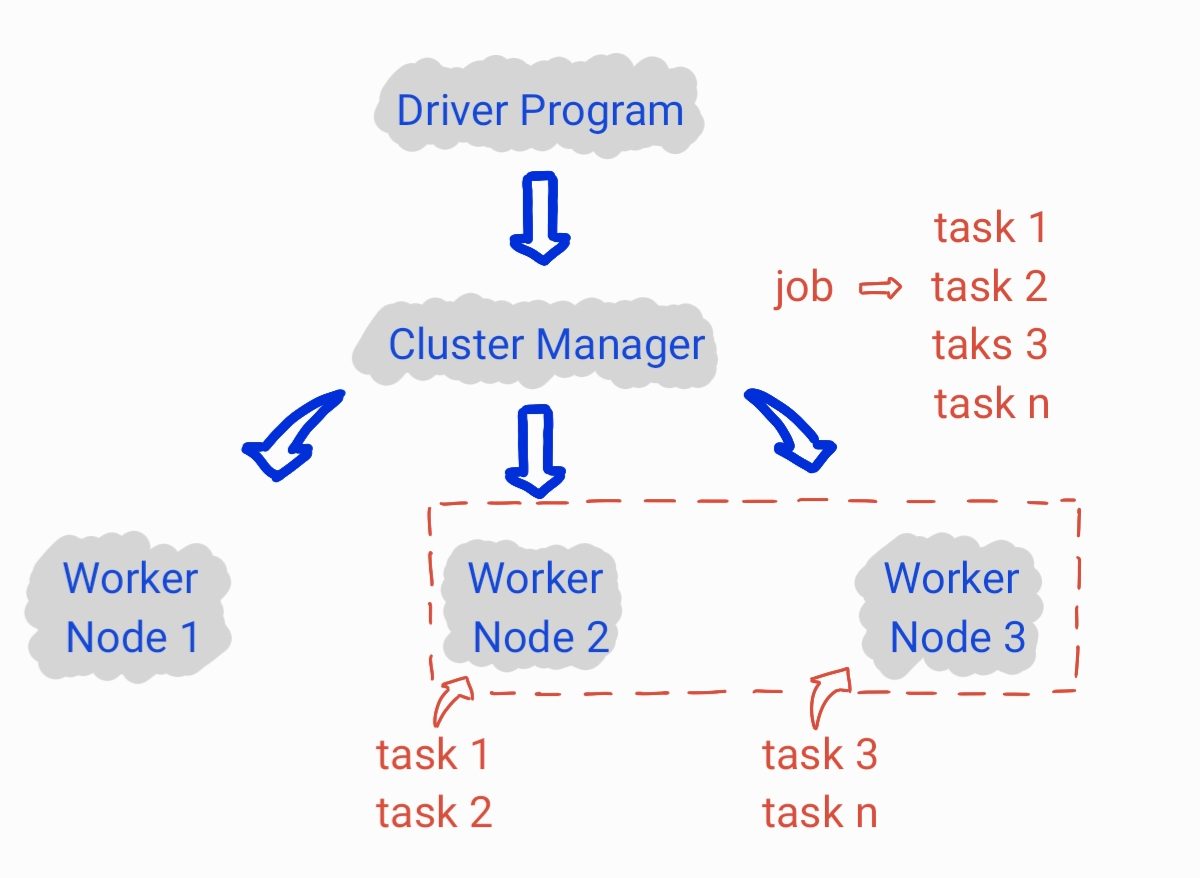
- Driver Program
O Driver Program corresposde ao programa principal que desenvolvemos e submetemos através de um SparkContext.
-
- Cluster Manager
O Cluster Manager é responsável pelo gerenciamento e alocação de recursos.
-
- Worker Nodes
Os Worker Nodes são de fato os executores que realizam o processamento das tasks.
Arquitetura
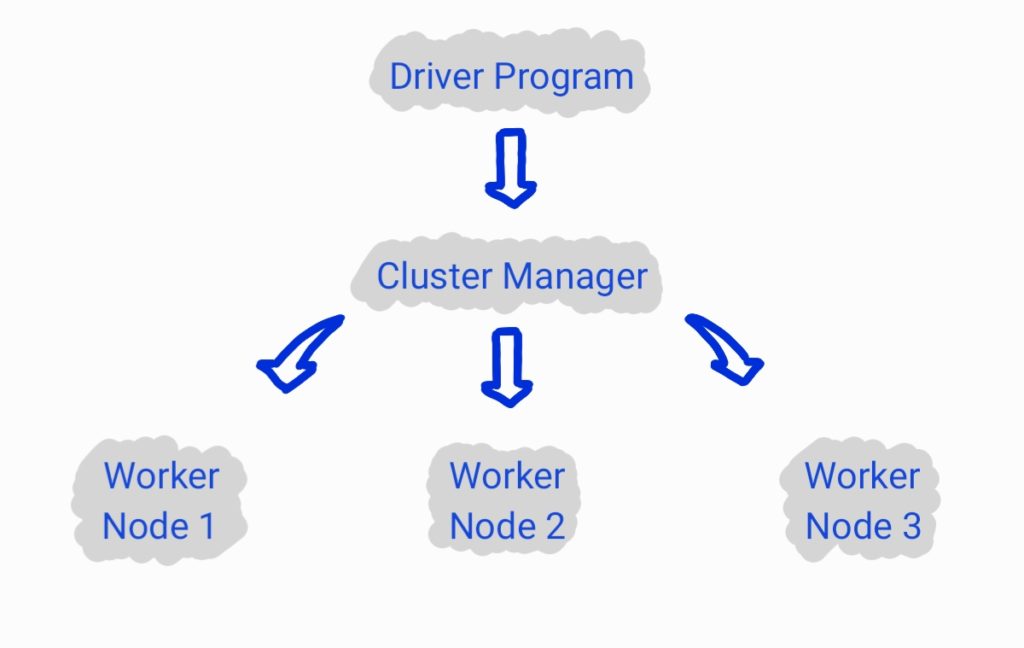
Funcionamento
O funcionamento de um job Spark tem início no Driver Program que, conforme já mencionado, é o programa que desenvolvemos. Durante o desenvolvimento, realizamos a conexão com o Cluster Manager através de um SparkContext (objeto pelo qual faremos a submissão de jobs spark):
from pyspark import SparkContext
-- instanciação de um contexto spark
sc = SparkContext(appName = "nome_da_aplicacao")A partir do momento em que instanciamos um SparkContext, o Cluster Manager é acionado para reservar os recursos necessários.
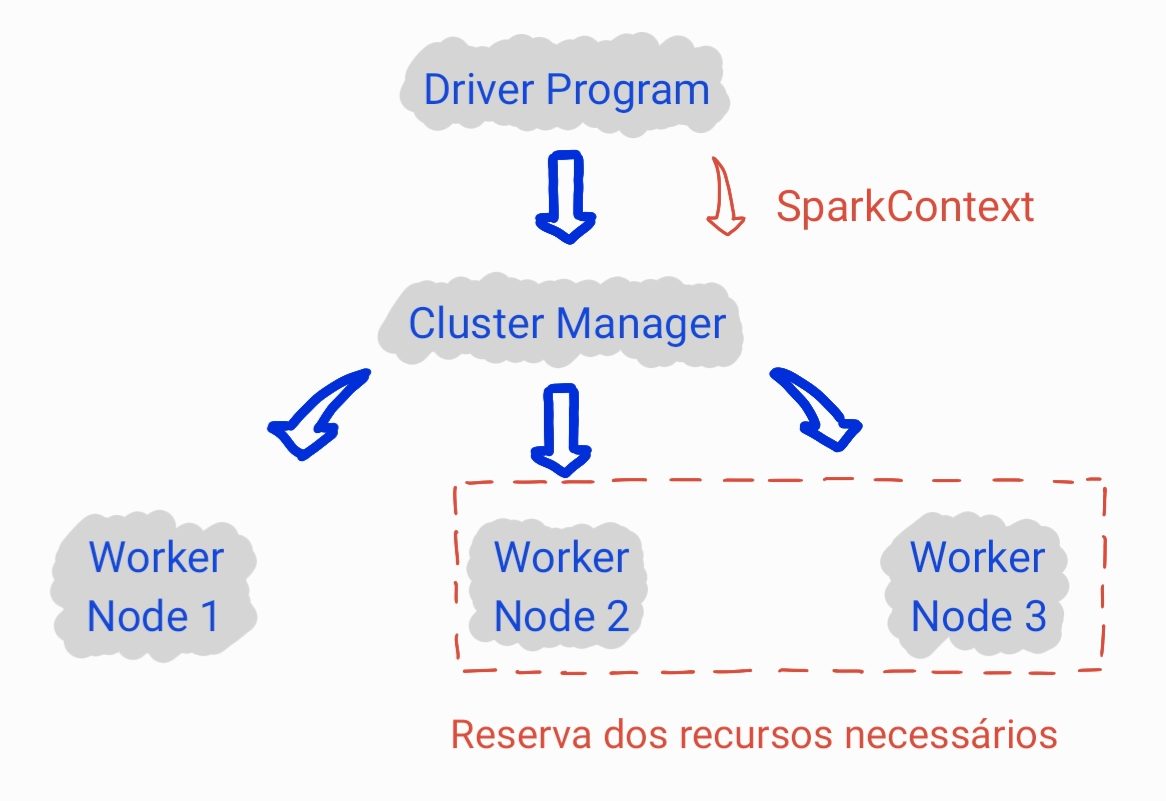
Com isso, damos sequência ao desenvolvimento do programa, fazendo a manipulação dos dados conforme necessário. Por exemplo, criando um dataframe spark:
-- instanciação de um contexto sql
sqlContext = SQLContext(sc)
-- criação de um dataframe spark
df = sqlContext.createDataFrame(
[('ana', 23),('joao',34)],
['nome', 'idade']
)
Até o momento, nenhum job foi enviado para o Cluster Manager, pois os jobs são apenas enviados quando uma ação é definida.
A partir do momento que definirmos uma ação, por exemplo:
-- quantidade de registros do dataframe
df.count()
Dai sim temos o envio do job para o Cluster Manager.
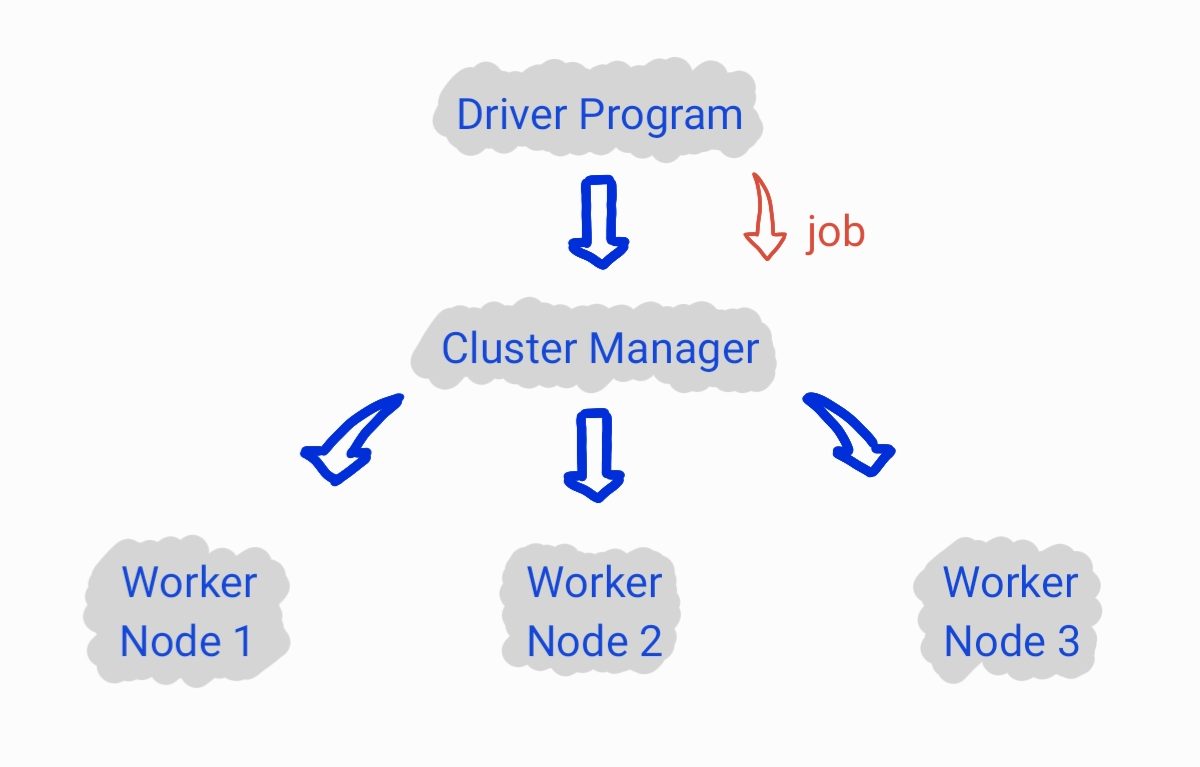
Quando o Cluster Manager recebe um job a ser executado, ele faz a separação do job em tasks que possam ser executadas paralelamente por diferentes executores. Tendo as tasks definidas, elas são distríbuidas para os Worker Nodes e executadas.