Ao utilizarmos Spark para processar os dados de forma distribuida através do cluster, é de extrema importância saber definir os recursos utilizados pelo nosso Driver Program. A configuração indevida dos recursos em nosso programa pode levar ao desperdício de CPU e memória do cluster e consequentemente, aumento dos custos de uma arquitetura em nuvem, por exemplo.
Ao criar um contexto spark, uma das primeiras coisas que queremos definir é:
- a quantidade de cores utilizada por cada executor;
- a quantidade de executores dedicados ao job;
- a memória reservada para cada executor.
Para entendermos como definir cada um desses parâmetros, vamos explorar um pouquinho o que é um executor e pelo que ele é composto.
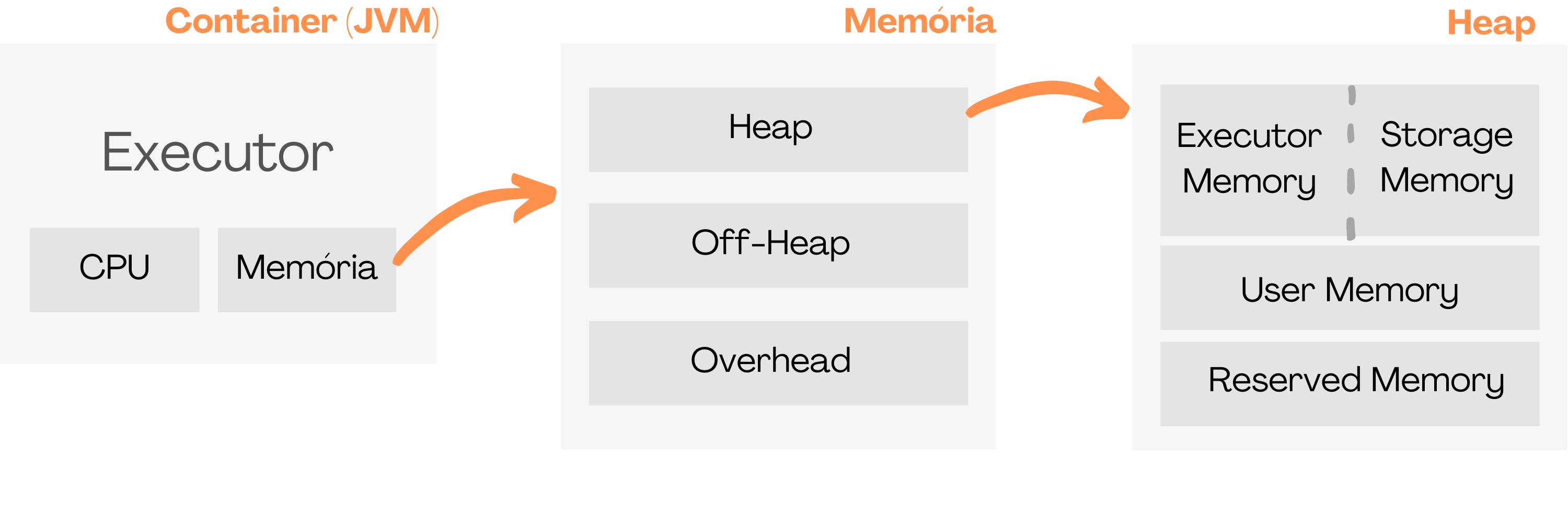
De forma simples, um executor é um container, com seus próprios recursos (memória e CPU).
Como está dividida a memória do container?
A memória do executor é dividida em três grupos: Heap Memory, Off-Heap Memory e Overhead Memory. Vamos nos aprofundar no primeiro grupo, o Heap.
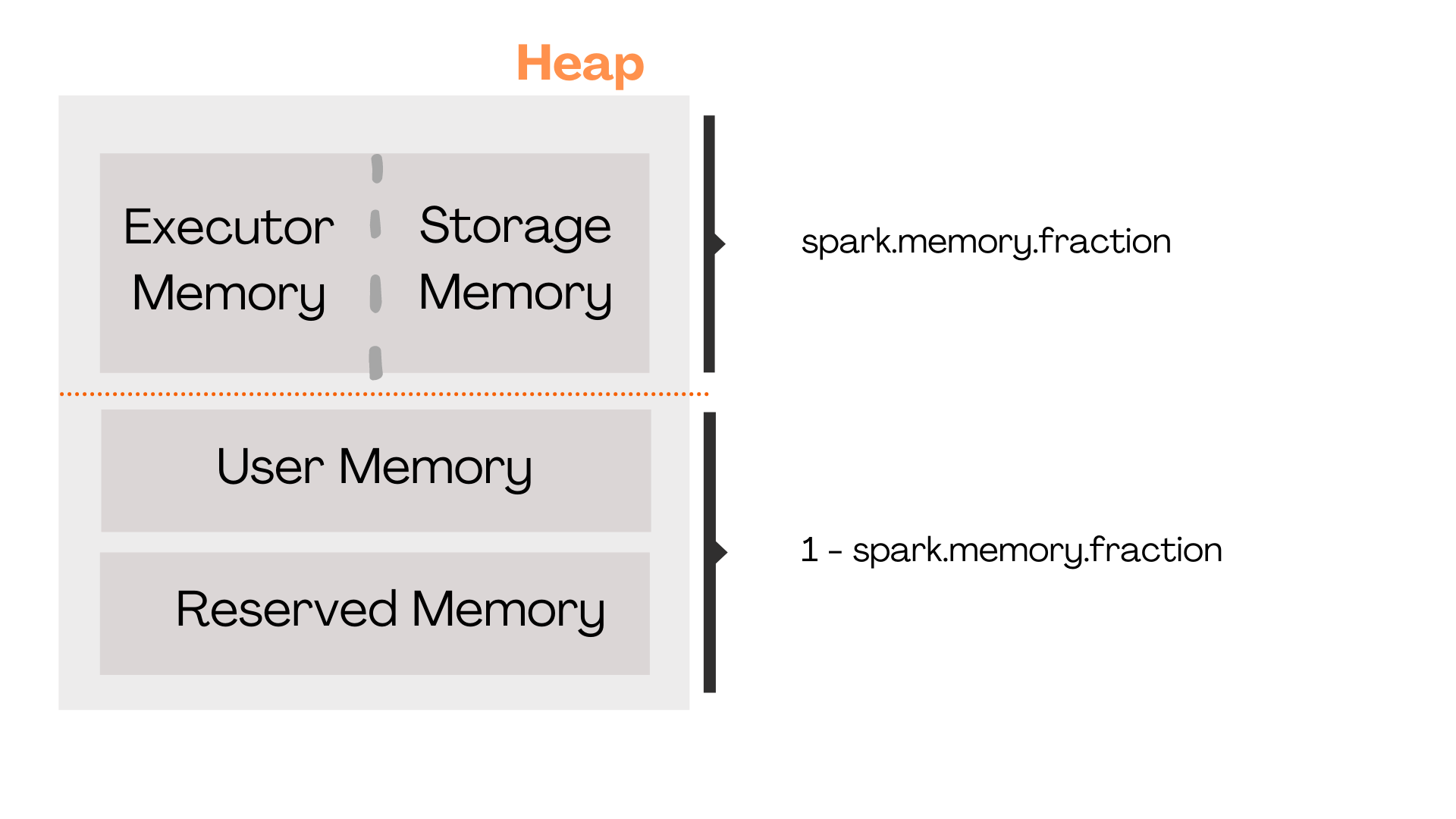
No Heap, temos a divisão em três novos grupos: User Memory, Reserved Memory e Execution e Usage Memory. O Execution e Usage Memory compartilham uma fração da memória com uma dinâmica de compartilhamento entre eles (parametrizável), essa dinâmica é chamada de Dynamic Occupancy Mechanism
O Reserved Memory utiliza sempre 300MB. Portanto, sempre subtraimos esse valor da memória de nosso executor. A memória restante é dividida entre os dois grupos restantes, User Memory e Execution e Storage Memory. Essa divisão é determinada pelo parâmetro spark.memory.fraction, que indica qual fração da memória será dedicado ao Execution e Storage (conjuntamente).
spark.memory.fraction: fração da memória Heap do executor reservada para Execution e Storage.
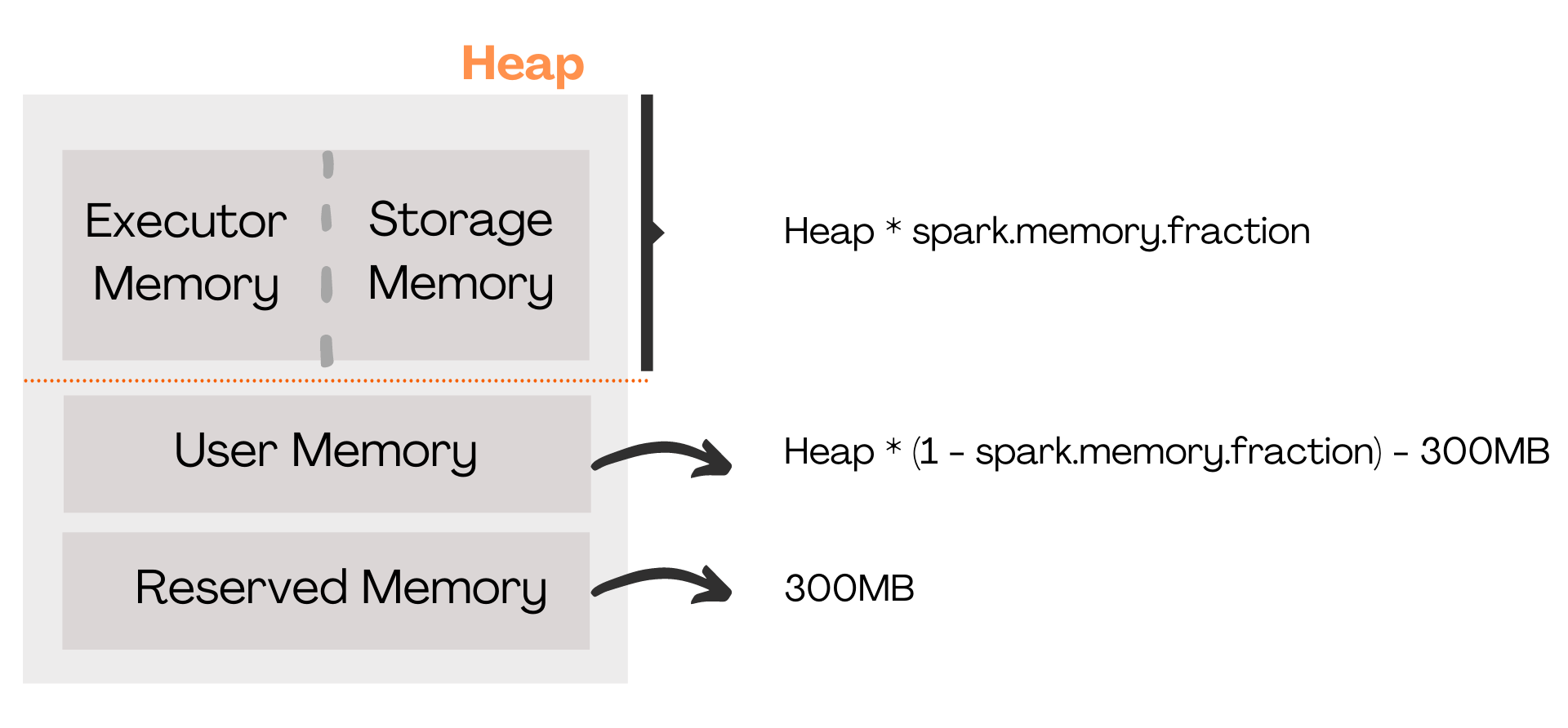
Com isso, temos que:
Reserved Memory = 300MB
Execution e Storage Memory = Heap * spark.memory.fraction
User Memory = Heap * (1 – spark.memory.fraction) – 300MB
O Execution e o Storage compartilham a memória entre si, porém priorizando a execução de Tasks. Isso significa que se o Executor necessitar de memória e ela já estiver ocupada para o armazenamento de dados (cache de dataframes, por exemplo), ele poderá enviar esses dados para o disco, liberando memória para seu uso próprio.
É possível determinar um percentual desse espaço compartilhado que, se estiver em uso pelo Storage, os dados não poderão ser limpados (enviados para o disco). Esse percentual é determinado pelo parâmetro spark.memory.storageFraction. Importante frisar que caso o Executor não tenha memória durante sua execução, sua aplicaçao dará erro.
spark.memory.storageFraction: fração da memória compartilhada pelo Executor e Storage que, uma vez ocupada pelo Storage, não pode ser limpada para utilização do Executor.
No próximo artigo, veremos como definir os executores, a quantidade de cores e a memória para o nosso job!