No último post, entendemos como a memória dos executores está dividida, como é definido o espaço de cada grupo e o que são os parâmetros spark.memory.fraction e spark.memory.storageFraction. Nesse artigo, vamos ver o que são os parâmetros spark.executor.cores, spark.executor.instances e spark.executor.memory e entender como defini-los da melhor forma.
Os parâmetros
spark.executor.cores: indica quantos cores serão designados para cada um dos executores.
spark.executor.instances: indica quantos executores serão dedicados ao seu job.
spark.executor.memory: indica quanta memória será dedicada a cada executor.
Estrutura do cluster
Para entendermos como determinar cada um desses parâmetros de forma a otimizar os recursos do cluster, vamos reelembrar como o cluster está estruturado:
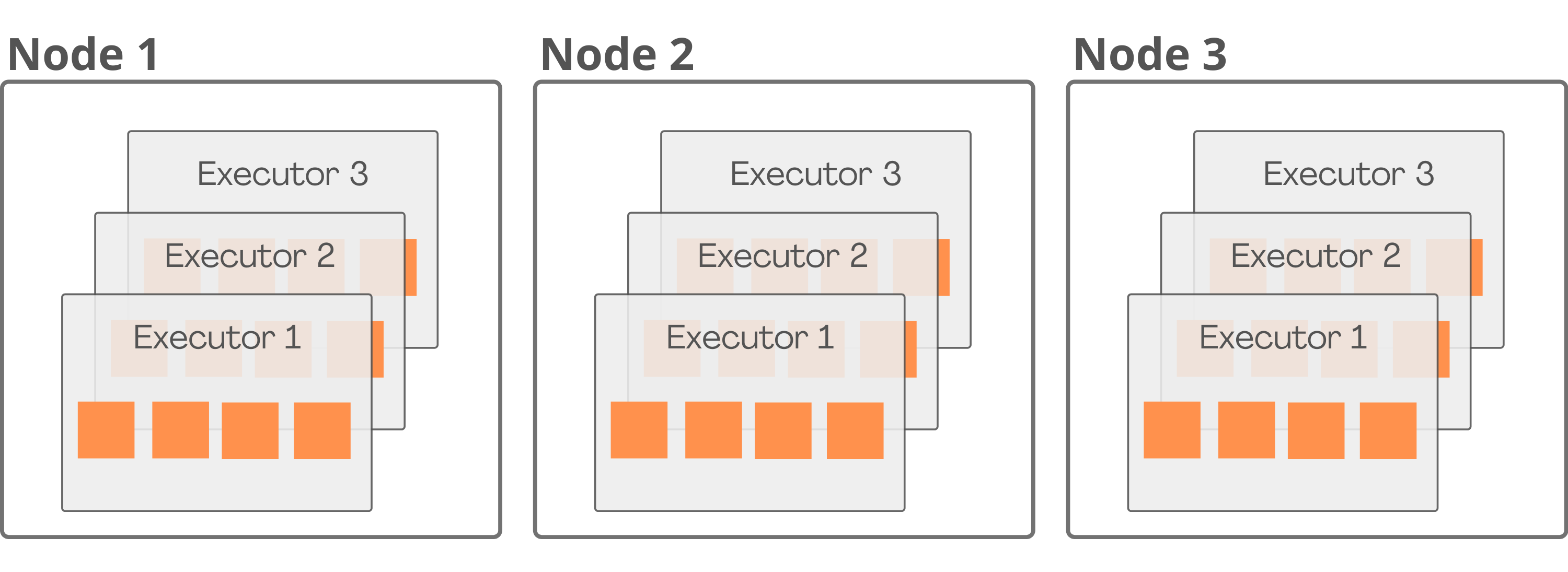
De forma simples, o cluster está separado em nodes. Os nodes são compostos pelos executores que, por sua vez, são compostos por cores.
Definindo os parâmetros
Para definirmos os recursos utilizados pelo nosso job, devemos seguir os seguintes passos:
1) Determinação da quantidade de cores por executores
O primeiro passo é determinar quantos cores serão utilizados em cada executor. Cada core fará o processamento de uma task, portanto, em cada executor há uma paralelização da execução das tasks através dos cores. Essa paralelização tem como consequência uma diminuição no tempo de processamento. Os cores do executor irão compartilhar a memória do executor, o que significa que determinar uma quantidade de cores muito alta, levará a uma perda de performance dado que a memória não será suficiente para processamento e armazenamento e os dados poderão ser despejados para o disco, ou então, a memória será muito grande para o Garbage Collector fazer a sua limpeza performaticamente.

Sendo assim, é necessário garantir que a quantidade de cores não seja pequena o suficiente para perder o paralelismo da execução, nem grande o suficiente para perder performance. O número recomendado é de 5 cores por executor.
spark.executor.cores = 5
2) Determinação da quantidade de executores
Tendo a quantidade de cores por executor setada, podemos determinar quantos executores teremos dedicado ao nosso job. A determinação desse parâmetro depende diretamente da estrutura do seu cluster e do parâmetro spark.executor.cores que você determinou.
O primeiro passo é entender quantos cores há por node no nosso cluster e quantos nodes serão dedicados ao nosso job.
Suponhamos que definimos que teremos 2 nodes dedicado ao job e que em cada node há 16 cores. Teríamos o seguinte cenário:
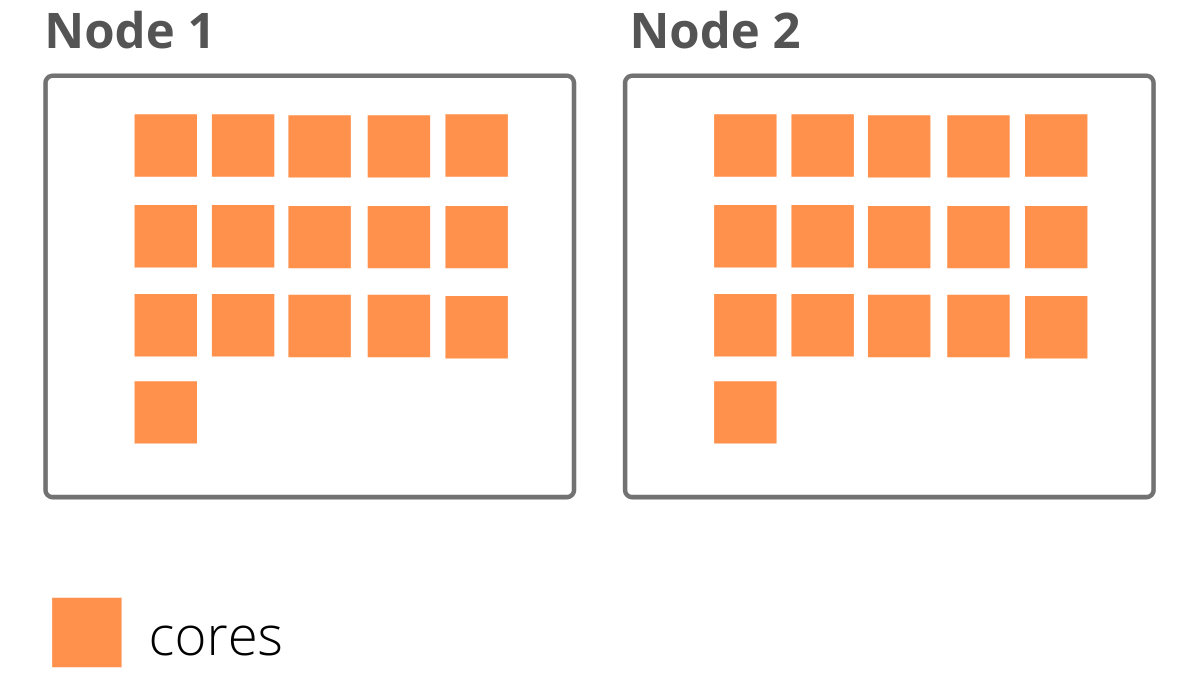
Dos cores que temos disponíveis, para cada node, será necessário reservar uma parcela para gerenciamentos do Hadoop, portanto, o próximo passo seria determinar quantos cores temos realmente disponível para processamento em cada node. Equivalente à:
quantidade de cores no node – quantidade de cores dedicados ao gerenciamento
Geralmente, usa-se um core por node para o gerenciamento do Hadoop, portanto, temos de fato 15 cores em cada node dedicado ao processamento do nosso job.
Com essas informações, já conseguimos determinar a quantidade de executores nos nossos nodes da seguinte forma:
\frac{qt\char`_cores\char`_por\char`_node - qt\char`_cores\char`_reservados}{qt\char`_cores\char`_por\char`_executor}
Sendo,
qt_cores_por_node = quantidade de cores no node (no exemplo acima, seriam 16)
qt_cores_reservados = quantidade de cores no node reservado para o gerenciamento do Hadoop (no exemplo acima, seria 1)
qt_cores_por_executor = quantidadade de cores em cada executor (definimos 5)
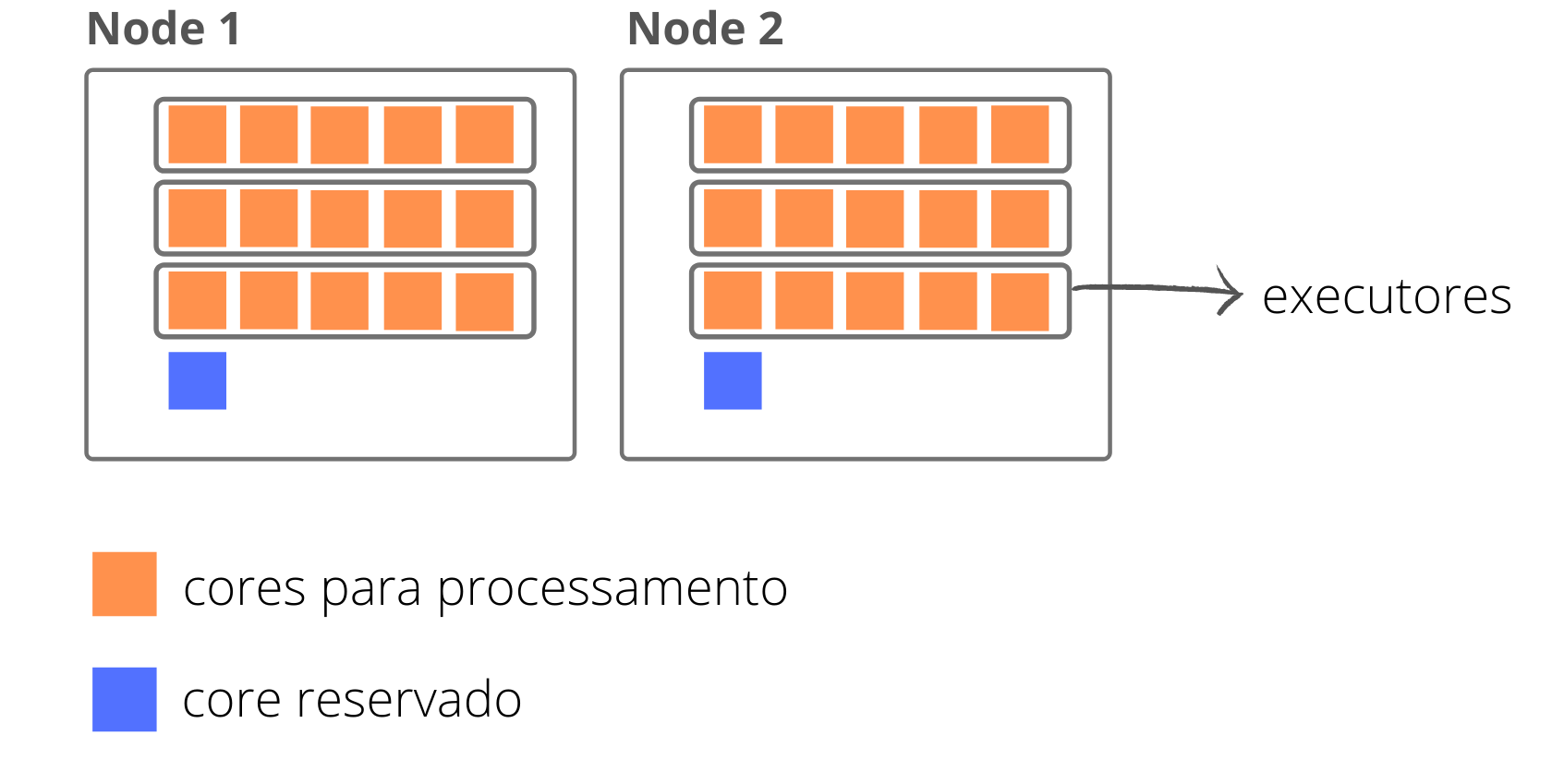
Com esse cálculo, temos a quantidade de executores por node, que no nosso caso seria:
\frac{16 - 1}{5} = 3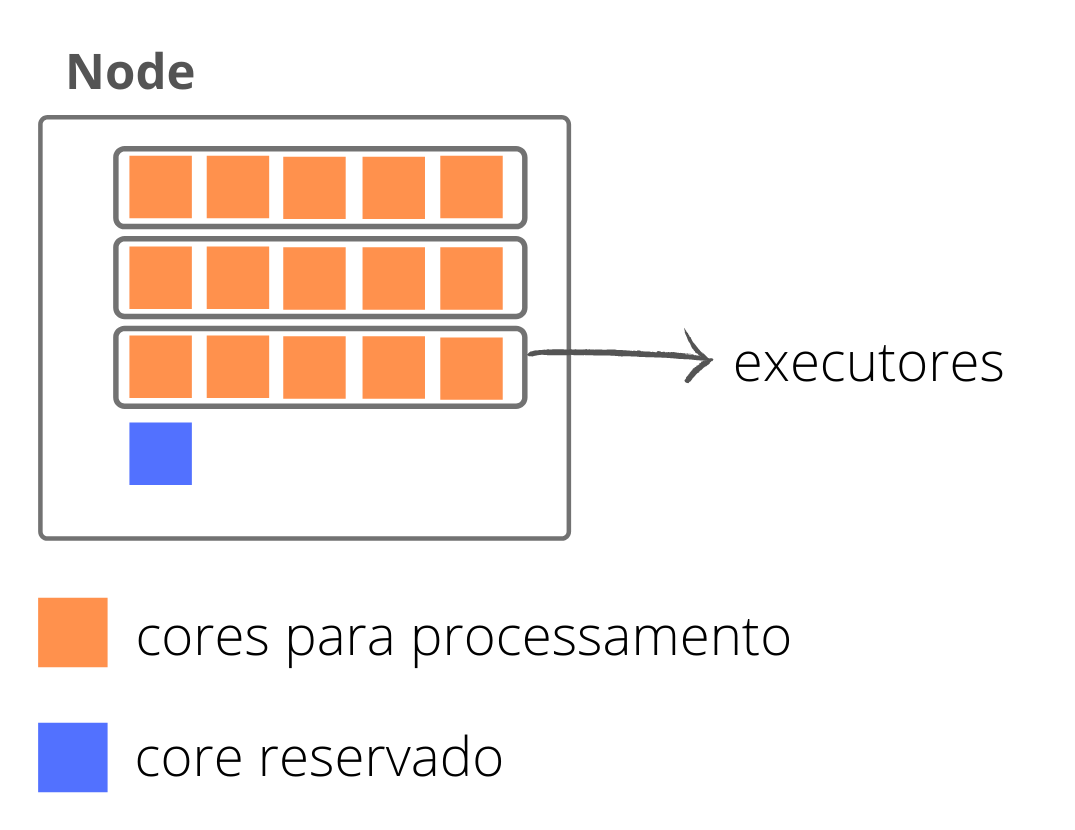
Tendo calculado a quantidade de executores por node, o próximo passo é multiplicar essa quantidade pela quantidade de nodes dedicados ao nosso job.
3 \cdot 2 = 6
Nesse cenário, temos a seguinte estrutura:
Porém, além dos executores dedicados ao processamento, é necessário reservar um para atuar como o nosso driver. Caso mantivéssmos o parâmetro spark.executor.instances = 8, o driver seria alocado para um novo node, o que levaria ao desperdício de todos os cores restantes do node adicional durante a execução de nosso job.
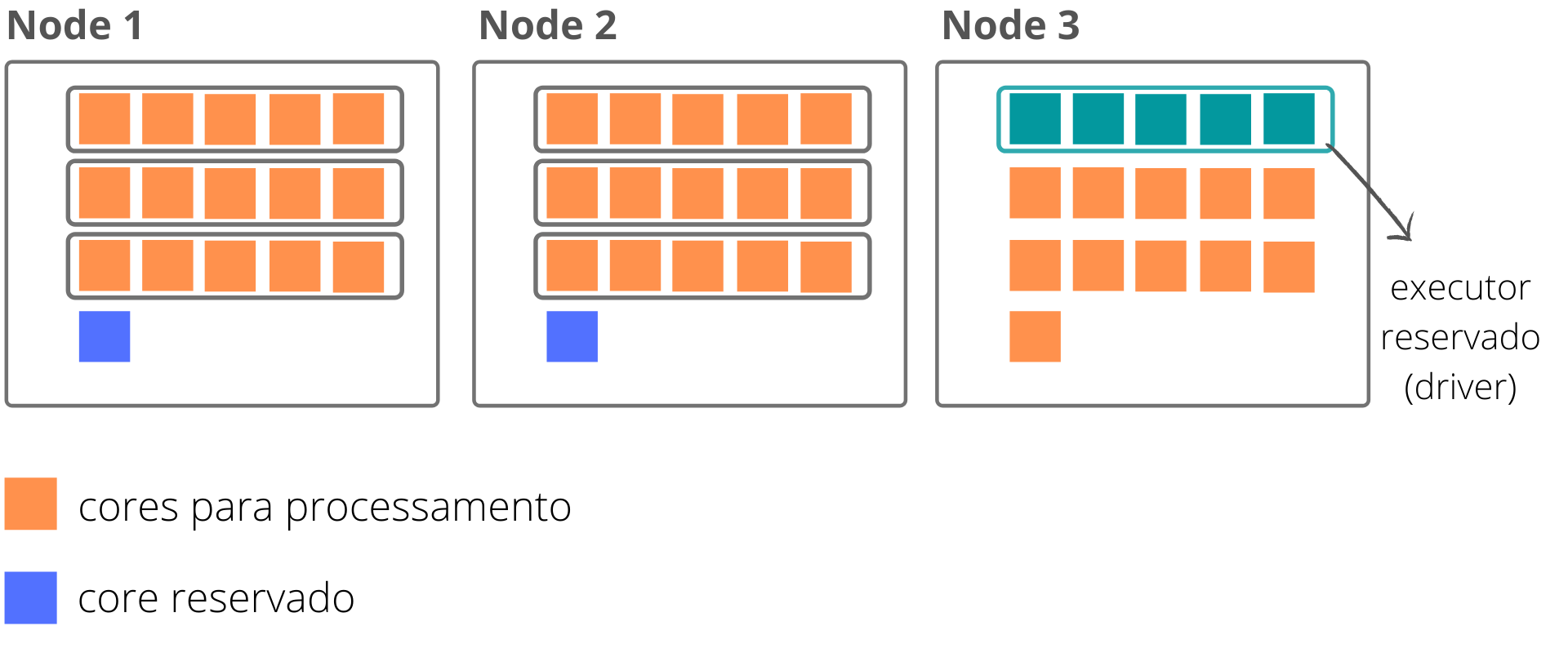
Portanto, temos que substrair um executor da nossa quantidade final que será dedicada ao Application Master (no caso do gerencialmento pelo Yarn). Com isso, temos:
3 \cdot 2 - 1 = 5
spark.executor.instances = 5
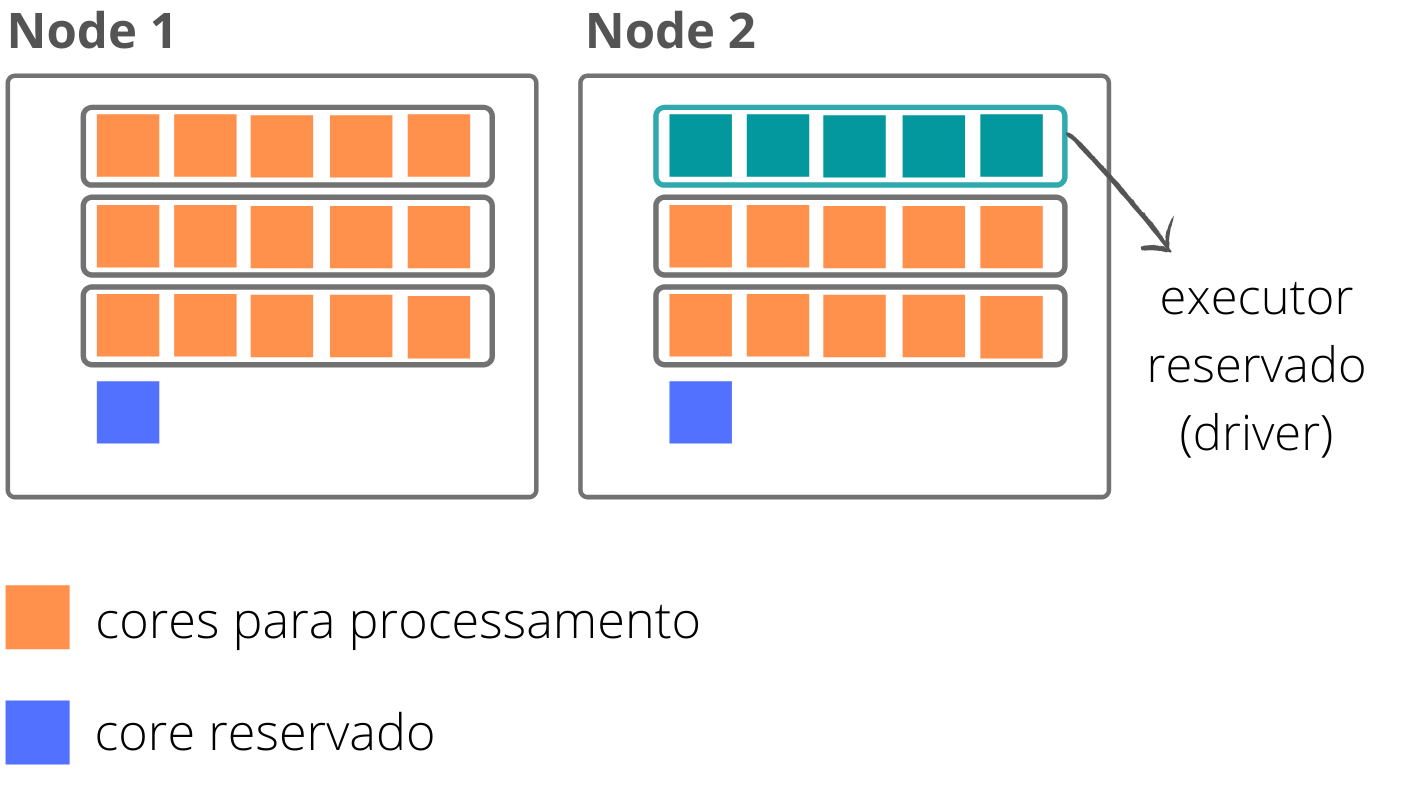
3) Determinação da memória por executor
O último passo é determinar quanto será alocado de memória para cada um dos executores. Para determinar esse parâmtro, precisamos saber:
- a memória disponível em cada node
- a quantidade de nodes que será usada em nosso job
- a quantidade de executores por node
O primeiro passo, é ver quanto de memória há disponível em cada node de nosso cluster, que pode ser checado no Cluster Manager. Suponhamos que tenhamos 112GB.
memória disponível em cada node = 112GB
O segundo passo é determinar quanta memória será consumida por cada um dos executores do node. No nosso caso, temos 3 executores por node, portanto, a memória de cada executor equivale à
\frac{112}{3} = 37,3GB
Essa memória equivale à toda a memória do nosso executor, porém, conforme já vimos, a memória do executor é separada em Heap, Off-Heap e Overhead. O parâmetro spark.executor.memory corresponde à memória do Heap e Off-Heap, logo, antes de determinar o parâmetro, precisamos desconsiderar a memória Overhead.
A memória separada para Overhead é determinada pelo parâmetro spark.executor.memoryOverhead, que assume por padrão o valor máximo entre executorMemory * 0.10 e 384MB.
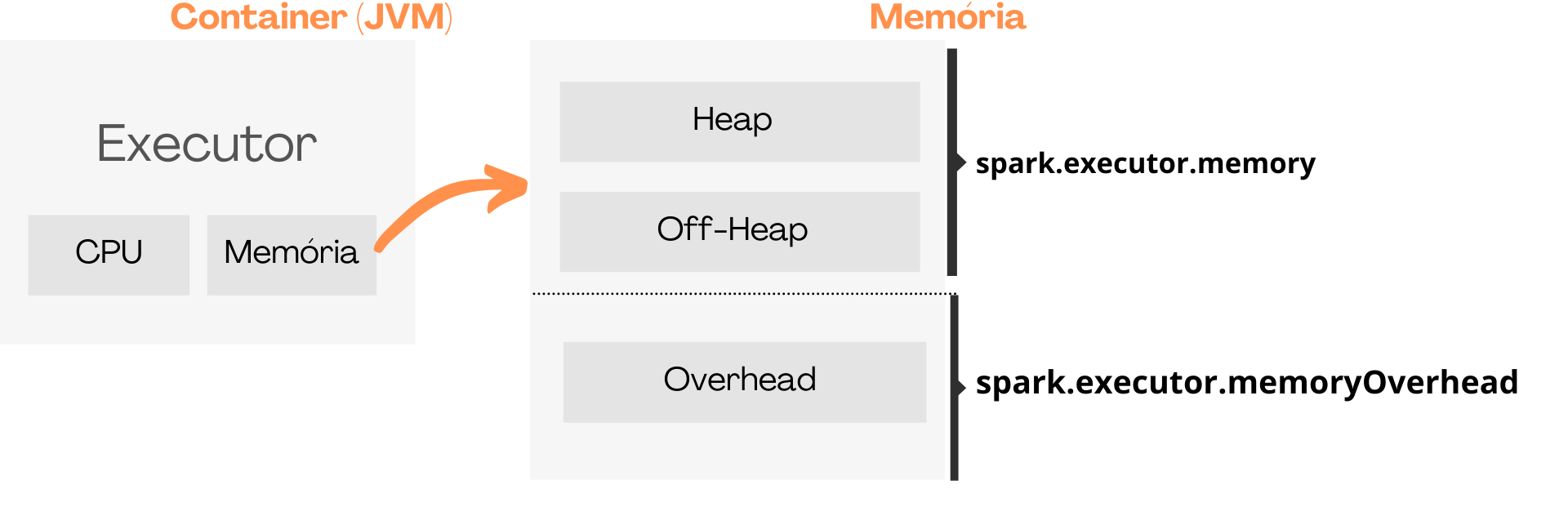
O último passo é determinarmos quanto da memória do executor será dedicado à Overheap e subtrair da memória do executor, assim obtemos o parâmetro spark.executor.memory.
0,1 \cdot 112GB = 11,2GB\\
11,2GB>384MB\\
\therefore memoryOverhead = 11,2GB \\
memory = 37,3GB - 11,2GB \\
\therefore memory = 26,1\\
Portanto,
spark.executor.memoryOverhead = 11,2GB
spark.executor.memory = 26,1GB
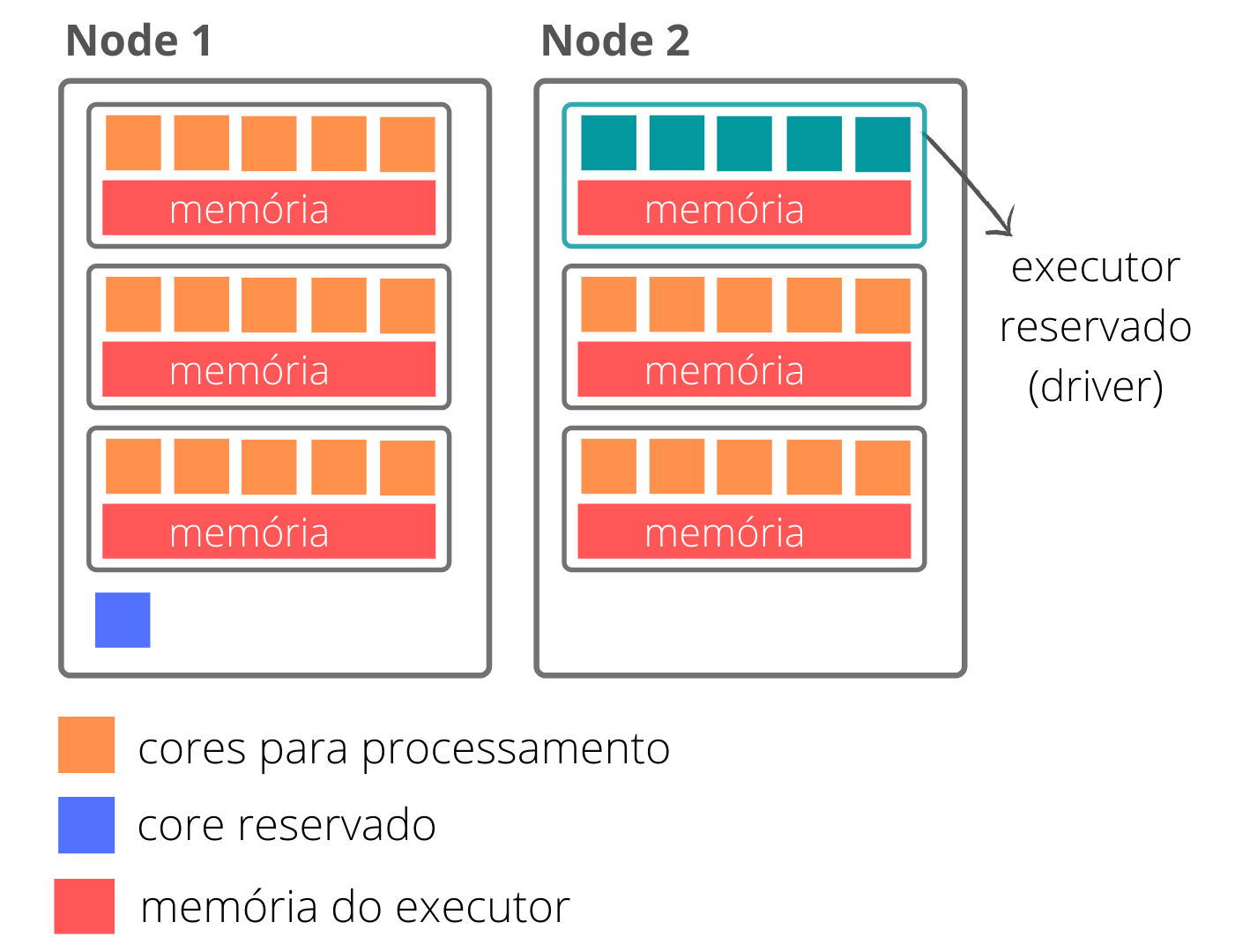
O cenário apresentado exemplifica o aproveitamento de todo o recurso existente no node dedicado ao job. Caso seja necessário mais ou menos recursos para o seu processo, é desejavel ajustar proporcionamente todos os parâmetros, assim, evitamos que um node seja utilizado para um processo sem o aproveitamento de toda sua capacidade, levando a um despedício de recursos do cluster durante a execução de nosso job.